各种数据在计算机中表示的形式称为机器数,其特点是符号位与数值位一起编码,数的符号用0、1表示,小数点隐含表示并不占位置。机器数对应的实际数值称为数的真值。
机器数包括无符号数和有符号数两种。对于带符号数,机器数的最高位是表示正、负的符号位,其余位表示数值。若小数点位置在最低数值位之后,则是纯整数;若小数点位置在最高数值位之前(符号位之后),则是纯小数。
1. 常用码制
带符号机器数可采用原码、反码、补码和移码等不同编码方法,这些编码方法称为码制。
(1)原码表示法。编码规则是:符号位为0表示正,为1表示负,数值部分用该数绝对值的二进制数表示。用原码表示整数时,小数点隐含在最低位之后;用原码表示纯小数时,小数点隐含在符号位和数值位之间,均不占位。通常用[X]原表示数X的原码。例如,设机器字长为8位,则有下列结果:

按照原码编码规则,零有两种表示形式。
原码表示方法简明易懂,与其真值转换方便,比较容易进行乘除运算,但是在进行加减运算时,原码运算不方便,主要源于符号位不能参加运算,需要增加很多判断条件。
(2)反码表示法。编码规则是:符号位为0表示正,为1表示负,正数的反码等于原码,负数的反码等于原码除符号位外按位取反,即0变1.1变0.通常用[X]反表示数X的反码。例如,设机器字长为8位,则有下列结果:

按照反码编码规则,零也有两种表示形式,反码同样不方便运算。
(3)补码表示法。编码规则是:符号位为0表示正,为1表示负,正数的补码等于原码,负数的补码等于反码末位加1.通常用[X]补表示数X的补码。例如,设机器字长为8位,则有下列结果:

按照补码编码规则,零有唯一的表示形式。
采用补码进行加减运算十分方便,可以允许符号位一起参与运算,而且可以把减法运算转化为加法运算,提高了运算速度。
(4)移码表示法。编码规则是:把数据加上一个偏移量,当机器字长为n,偏移量为2n-1时,将补码的符号位取反就得到对应的移码。例如,设机器字长为8位,则有下列结果:

2. 定点数和浮点数
在机器数中,按照小数点位置是否固定,把机器数分为定点数和浮点数两种。
(1)定点数。小数点位置固定不变的数叫做定点数。通常包括两种类型:定点整数(纯整数,小数点在最低有效数值位之后)、定点小数(纯小数,小数点在最高有效数值位之前)。
设机器字长为n,各种码制下带符号定点数的范围如表1-2所示。
表1-2 各种码制下带符号定点数的范围(机器字长=n)

(2)浮点数。小数点位置不固定的数叫做浮点数,浮点数主要用来表示实数。
一个实数总可以表示成一个纯小数和一个乘幂之积,例如:56.725=102×(0.56725)、-1894.0456=104×(-0.18940456),二进制数据也可以这样表示。一个二进制数N通常表示为如下形式:
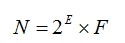
其中E称为阶码,F称为尾数。用阶码和尾数表示的数叫做浮点数,这种表示数的方法称为浮点表示法。
在浮点表示法中,阶码通常是带符号的纯整数,尾数是带符号的纯小数,表示格式如下:

在浮点表示法中,阶码决定数值范围,尾数决定数值精度。通常采用规格化浮点数来比表示尾数,将尾数的绝对值限制在区间[0.5. 1],从而表示更多的有效数字。当尾数用补码表示时,需要注意下述问题:
· 若尾数,则其规格化的尾数形式为:F=0.1×××…×,其中×可为0.也可以为1.即将尾数限定在区间[0.5.1].
· 若尾数,则其规格化的尾数形式为:F=1.0×××…×,其中×可为0.也可以为1.即将尾数限定在区间[-1.-0.5].
如果浮点数的阶码(包括一位阶符)用R位移码来表示,尾数(包括一位数符)用M位补码表示,则这种浮点数的表数范围为:
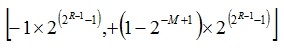
很明显,一个数的浮点表示法不唯一,这就容易导致不同计算机之间数据格式的不兼容性。为此,IEEE制定了浮点数表示的工业标准IEEE754.被广泛使用。该标准表示形式如下:
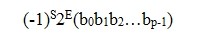
其中,(-1)S称为数符,当s为0时表示正数,当s为1时表示负数;E为阶码,用移码表示;(b0b1b2…bp-1)是尾数,用原码表示,p是尾数的长度,它表示尾数共p位。
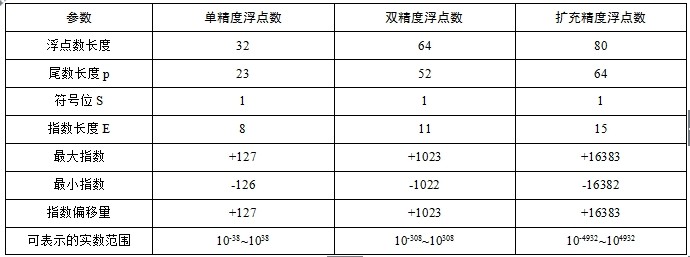
目前,计算机中主要使用3种形式的IEEE754浮点数,如表1-3所示。
表1-3 三种不同类型的IEEE754浮点数
单精度、双精度浮点数格式如图1-10所示,从中可以看到IEEE754中的尾数最高位b0总是1.而且它和小数点一样隐含存在,在机器中并不明确表示出来。
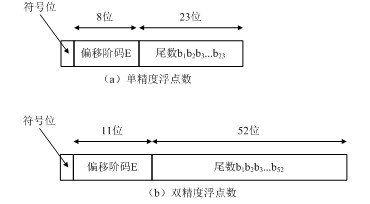
图1-10 单精度、双精度IEEE754浮点数格式
例如,将十进制数178.125表示成单精度浮点数。首先将178.125表示成二进制形式:(178.125)10=(10110010.001)2.再将二进制实数表示成规格化形式:10110010.001=1.0110010001×27.所以符号位s=0.尾数=01100100010000000000000.阶码E=(7+127)10=(134)10=(10000110)2.即十进制数178.125对应的单精度浮点数形式为:
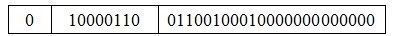
又如,可以根据下述单精度浮点数,求出其对应的十进制数值。
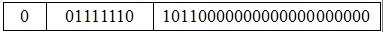
指数=E-127=(01111110)2-127=126-127=-1.尾数=1.1011.所以该浮点数的数值为1.1011*2-1=(0.11011)2=(0.84375)10.
3. 二-十进制编码
用4位二进制代码表示1位十进制数,称为二-十进制编码,简称BCD编码。根据4位代码中每一位是否有确定的权来划分,可分为有权码和无权码两类。
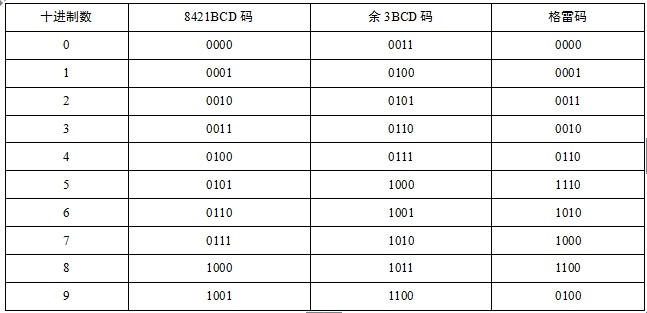
应用最多的有权码是8421码,即4个二进制位的权从高到低分别为8、4、2和1.无权码中用得较多的是余3码和格雷码。余3码是在8421码的基础上,把每个数的代码加上0011后构成的。格雷码的编码规则是相邻的两个代码之间只有一位不同。
常用的8421BCD码、余3码、格雷码与十进制数的对应关系如表1-4所示。
表1-4 8421BCD码、余3码、格雷码与十进制数的对应关系
4. 字符表示法
字符编码就是为每个字符确定一个对应的整数值,以及相对应的二进制编码。常用的字符编码标准有ASCII字符编码标准以及IBM公司提出的EBCDIC代码等,其中ASCII码的应用范围最广。国际标准化组织(ISO)和我国都颁布了与ASCII编码一致的编码(ISO-646和GB-1988-80)。
ASCII码采用7个二进制位对字符进行编码:低4位组d3d2d1d0用作行编码,高3位组d6d5d4用作列编码,其格式如图1-11所示。
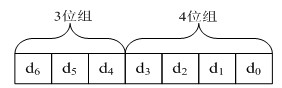
图1-11 ASCII码编码格式
采用7位编码构成的ASCII码基本字符集只能表示128个字符,不能满足信息处理的需要,所以对ASCII码基本字符集进行扩充,采用一个字节(8位二进制数)表示一个字符,一共可以表示256种字符和图形符号,称为扩充的ASCII码字符集。
5. 汉字表示法
汉字种类繁多,编码比拼音文字困难,而且在同一汉字处理系统中,输入、内部处理、存储和输出对汉字代码的要求不同,所以编码也不相同,关键是要进行一系列汉字代码转换。
按照计算机中汉字处理流程,汉字编码一般分成输入码、内部码和字形码三种。
(1)输入码。输入码的作用是考虑如何把汉字输入到计算机内,常用输入码包括下述四种:
· 数字编码:用一串数字来表示汉字的编码方法。
· 字音编码:一种基于汉语拼音的编码方法。
· 字形编码:将汉字字形分解归类,得到基本字形,汉字由基本字形组成。
· 形音编码:吸取了字音编码和字形编码的优点。
在上述输入码基础上,近年来,基于统计和学习功能的、以词语(短语)或句子作为输入单位的输入方法效率高,很受用户欢迎。
输入码和内部码、字形码属于完全不同的范畴,使用不同的输入码输入同一个汉字,它们对应的内部码、字形码完全相同。
(2)内部码。汉字内部码(简称汉字内码)是在设备和信息处理系统内部存储、处理、传输汉字用的代码,这种代码仅仅存在于中文计算机中。
1981年我国颁布了《信息交换用汉字编码字符集·基本集》(GB2312-80),在其中规定了汉字国标码,它采用两个字节存放一个汉字的内码,每个字节使用低7位,为了与标准ASCII码兼容,每个字节只使用94个编码。
GB2312-80国标字符集由三部分组成。第一部分是字母、数字和各种符号,共682个;第二部分是一级常用汉字,共3755个,按汉语拼音排列;第三部分是二级常用字,共3008个,不是太常用,采用偏旁部分排列。
GB2312国标字符集构成一个二维平面,它分为94行、94列,行号称为区号,列号称为位号。每一个字符在码表中都有唯一的位置编码,该编码就是字符所在区号(行号)及位号(列号)的二进制编码(区号在左,位号在右),称为"区位码".
但区位码并不是国标码,由于信息传输的原因,每个汉字的区号和位号必须分别加上32.构成的新代码就是国标码。
计算机中的双字节汉字与单字节西文字符经常混合在一起处理,容易混淆,所以需要对汉字信息进行标识。通常是把汉字两个字节的最高位都置为"1",置"1"后的双字节汉字编码就称为汉字"机内码",简称"内码".
为了统一地表示世界各国文字,1993年国际标准化组织公布"通过多八位编码字符集"的国际标准ISO/IEC 10646.简称UCS.它包含了中、日、韩等国的文字。微软、IBM等公司联合制定的工业标准Unicode(统一码或联合码),就是为此而提出。我国在1994年制定了与ISO/IEC 10646等同的国家标准Gb13000.
(3)字形码。汉字字形码是表示汉字字形的字模数据,通常采用点阵、矢量函数等方式来表示。
采用点阵形式时,汉字字形码就是这个汉字字形点阵的代码,它采用一组排成方阵的二进制位数字来表示一个汉字。这种表示形式所占存储空间相当大。
采用矢量函数形式时,用一组直线和曲线来勾画汉字、字母和符号中笔画的轮廓,记下每一条直线和曲线的数学描述(端点及控制点坐标)。这种方式输出之前必须经过复杂的运算处理,转换成点阵形式。Windows中使用的TrueType字库采用的就是这种表示形式。
6. 校验方法及校验码
计算机中的数据在存储和传输过程中可能会发生错误,通常采用校验码的方法来检测传送的数据是否出错。一个编码系统中任意两个合法编码之间的不同的二进制位称为这两个码字的码距。该编码系统任意两个编码之间距离的最小值称为该编码系统的码距。码距是衡量编码方式抗错误能力的一个指标,码距越大,则错误编码个数越多,当数据出现错误时,出现在错误编码集合中的概率就越大,从而更容易发现错误。
常用的校验方法有奇偶校验方法、循环冗余校验方法、海明码校验方法,每种校验方法都有对应的校验码。
(1)奇偶校验方法。在每组数据信息上附加一个校验位,校验位的取值(0或1)取决于这组信息中1的个数和校验方式(奇或偶校验)。如果采用奇校验,则这组数据加上校验码后数据中1的个数应为奇数。如果采用偶校验,则这组数据加上校验码后数据中1的个数应为偶数。
奇偶校验方法的特点如下:
· 码距为2.可检验出奇数个位数出错的情况,但不能检验出欧数个位数出错的情况,但实际中两位同时出错的概率很低,该方法适用性比较强。
· 该方法只能发现错误,但不知错误的位置,所以不能自动纠正。
常用的奇偶校验码有三种:水平奇偶校验码、垂直奇偶校验码和水平垂直校验码。
· 水平奇偶校验码。对每一个数据的编码添加校验位,使信息位与校验位处于同一行。
· 垂直奇偶校验码。这种校验方法把数据分成若干组,一组数据占一行,排列整齐,再加一行校验码,针对每一列采用奇偶校验。例如,对于32位数据10100101 00110110 11001100 10101011进行垂直奇偶校验,如表1-5所示。
表1-5 垂直校验码的例子
· 水平垂直校验码。在垂直校验码的基础上,对每个数据再增加一位水平校验位,便构成水平垂直校验码。例如,对于32位数据10100101 00110110 11001100 10101011进行水平垂直奇偶校验,如表1-6所示。
表1-6 水平垂直校验码的例子
(2)循环冗余校验方法(CRC码)。该方法能够校验传送信息的对错,并且能自动修正错误,它广泛用于通信和磁介质存储器中。如图1-12所示,CRC编码格式是在位信息后加位检验码。

图1-12 CRC编码格式
CRC码长度为n=k+r位,所以又叫做(n,k)码,用C(x)表示被传送的位二进制信息位,用G(x)表示系统的生成多项式,则构成CRC码流程如下:

上式左边就是CRC码,所以CRC码的生成过程是"左移位→除去生成多项式得到余数→加上余数".发送信息时将CRC码传送给对方,对方接收到以后除以G(x),如果传输正确,则结果为0.否则根据余数的数值确定是哪位数据出错。
(3)海明码校验方法。海明码校验方法是奇偶校验的一种扩充,但其不同之处在于采用多位校验码,能够检测出具体错误位置并纠正,其原理是在数据中加入个校验位,将码距按照一定规则拉长。
r位校验码有2r个值,其中只有一个表示数据正确,剩下的2r-1个值表示数据中存在错误,如果
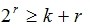
满足(k+r表示编码后的总长度),在理论上r位校验码就可以判断哪一位(包括信息位和校验位)出现问题,所以r位校验码最多可标明
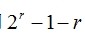
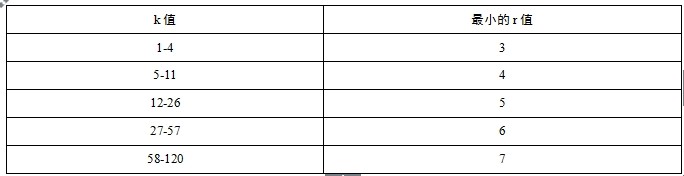
个错误信息。表1-7显示了数据位k与校验位r的对应关系。
表1-7 数据位k与校验位r的对应关系
CRC的编码规则是:海明码的总位数等于数据位与校验位之和,每个校验位Pi放在第2i-1个位置。以4位校验码为例,此时最多可以校验11位数据,设这11位数据是
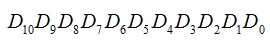
,其校验码是
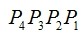
,所以对应的海明码是
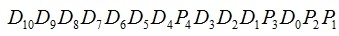
。海明码的每一位用多个校验位进行校验,被校验位号等于校验它的各个校验位位号和,各校验位的值为它参与校验的数据位的异或。11位数据对应的校验表如表1-8所示。
表1-8 11位数据海明码校验表
按照海明码编码规则,结合上表,可知其各校验位形成公式如下:
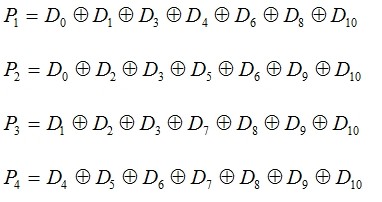
上述方式中的采用的是偶校验,当采用奇校验时,则取反。
海明码数据传送到接收方后,将各校验位的值与它所参与校验的数据位的异或结果进行异或运算。运算结果称为校验和,对于上述11位数据来说,校验和共有4个,如下所示:
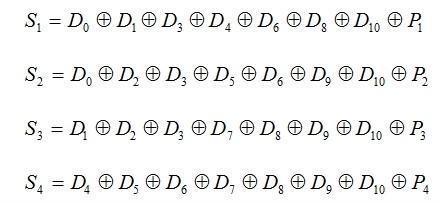
对偶校验来说,如果校验和不为0则表示传输过程中有错误,错误位置由4个校验和依序排列后直接指明。例如:
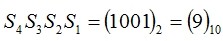
当时,就表明海明码第9位即D5发生了错误,此时把D5取反就纠正了错误。
当采用奇校验时,当校验位都是1时,表明传输没有错误,否则传输有错误。
微信扫一扫,领取最新备考资料


软考报考咨询
微信扫一扫,定制学习计划



湖南希赛网络科技有限公司 版权所有 ©2001-2026 湘ICP备10203241号-14 湘公网安备43019002000749号
违法和不良信息举报 举报电话:18974879411 举报邮箱:wujunping@educity.cn









