解释程序是一种语言处理程序,它实际是一台虚拟的机器,直接理解执行源程序或源程序的内部形式(中间代码)。因此,解释程序并不产生目标程序,这是它和编译程序的主要区别。图6-6显示了解释程序实现的3种可能情况。
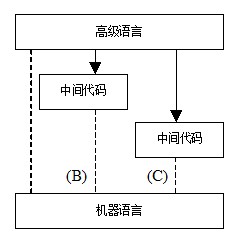
图6-6 解释程序实现的3种可能情况
在类型A的实现方案中,解释程序直接对源程序进行解释执行。这种解释程序对源程序进行逐字符的检查,然后执行程序指令表示的动作。例如,当解释程序扫描到字符串序列:
GOTO Label
解释程序意识到GOTO命令代表无条件跳转至Label所标识的位置,于是就开始搜索源程序中标号Label后面紧跟冒号":"的出现位置,然后跳转至该位置继续执行。这类系统在实现时需要反复扫描源程序,因此按类型A方案实现的解释程序效率很低,早期的解释性Basic语言就是采取该方案实现的。
在类型B的实现方案中,翻译程序先将源程序翻译成较贴近高级语言的高级中间代码,然后再扫描高级中间代码,对高级中间代码进行解释执行。所谓较贴近高级语言的高级中间代码,是指中间代码与高级语言的语句形式相像,两者存在着一一对应的关系。APL和SNOBOL4的实现很多都采用这种方法。
类型C又是一种解释程序的实现方案。类型C的解释程序和类型B的解释程序的不同点在于,类型C的解释程序首先将源程序转化成和机器代码十分接近的低级中间代码,然后再解释执行这种低级中间代码。一般说来,在这种实现方案下,高级语言的语句和低级中间代码之间存在着1-n对应关系。例如微软的C#语言,首先被编译成一种形式上较类似汇编语言的中间语言IL表示的代码,然后通过通用语言运行时(Common Language Runtime)解释执行IL程序。这类系统具有良好的可移植性。
下面对解释系统的结构做简单扼要的描述。这类系统通常可以分成两部分,第一部分包括通常的词法分析程序,以及句法和语义分析程序,它的作用仍是把源程序翻译成中间代码。第二部分是解释部分,用来对第一部分所产生的中间代码进行解释。由于真正的解释工作在解释部分完成,下面的介绍仅涉及第二部分。
用数组MEM来模拟计算机内存,(源程序的)中间代码程序和解释部分的各个子程序都存放在数组MEM中。全局变量PC是一个程序计数器,它记录了当前正在执行的中间代码位置。这种解释部分的常见的总体结构可以由下面两部分组成。
I1.PC=PC+1.
I2.执行位于opcode_table[MEM[PC]]的子程序(解释子程序执行后返回前面I1)。
用一个简单例子来说明其工作情况。设有两个实型变量A和B,A与B相加的中间代码是:
Start:Ipush
A
Ipush
B
Iaddreal
其中,中间代码Ipush,Iaddreal实际上都是opcode_table表的索引值(即位移),而该表单元中存放的值:
opcode_table[Ipush]= push
opcode_table[Iaddreal]= addreal
就是对应的解释子程序的起始地址,A和B都是MEM中的索引值,解释部分开始执行时,PC的值为Start-1.解释部分可表示如下:
interpreter_loop:
PC=PC+1;
goto opcode_table[ MEM [ PC ] ];
Push:
PC=PC+1
stackreal ( MEM [ MEM [ PC ] ] );
Addreal:
stackreal ( popreal ( ) + popreal ( ) );
goto interpreter_loop;
……
其中,stackreal表示把相应值压入下推栈,而popreal ( )表示把下推栈的栈顶元素取出,然后弹出栈顶元素。
微信扫一扫,领取最新备考资料


软考报考咨询
微信扫一扫,定制学习计划



湖南希赛网络科技有限公司 版权所有 ©2001-2026 湘ICP备10203241号-14 湘公网安备43019002000749号
违法和不良信息举报 举报电话:18974879411 举报邮箱:wujunping@educity.cn









